

搜索到
25
篇与
的结果
-

-
-
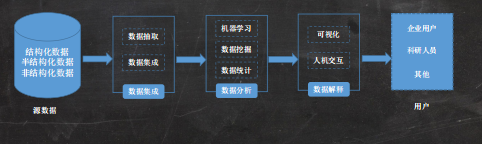
云计算与大数据 权威定义:云计算是一种将可伸缩、弹性、共享的物理和虚拟资源池以按需自服务的方式供应和管理,并提供网络访问的模式。• 狭义:云计算是一种提供资源的网络,使用者可以随时获取“云”上的资源,按需求量使用,并且可以看成是无限扩展的,只要按使用量付费就可以。• 是以一种方便的使用方式和服务模式,通过互联网按需访问资源池模型(例如网络、服务器、存储、应用程序和服务),以快速和最少的管理工作为用户提供服务1、关键特征:• 广泛的网络接入• 可测量的服务• 多租户• 按需自服务• 快速的弹性和可扩展性• 资源池化2、其它关键特征:• 虚拟化技术• 可靠性高• 性价比高1、按云部署模式和云应用范围分类:1)公有云• 一般是被一个云计算服务提供商所拥有,该组织将云计算服务销售给公众,公有云通常在远离客户建筑物的地方托管(一般为云计算服务提供商建立的数据中心)2)社区云• 云的基础设施被一些组织所共享,并为一个有共同关注点的社区服务。可以是该组织或某个第三方负责管理。3)私有云• 云的基础设施是为一个客户单独使用而构建的,因而提供对数据、安全性和服务质量的最有效控制。私有云可部署在企业数据中心中,也可部署在一个主机托管场所,被一个单一的组织拥有或租用。4)混合云• 云的基础设施由以上两种或两种以上的云(私有、社区或公有)组成。2、按云计算的服务层次和服务类型分类:1)基础设施即服务(Infrastructure as a Service,IaaS)• 提供虚拟化的计算资源,如虚拟机、存储、网络和操作系统。其核心技术是虚拟化。2)平台即服务(Platform as a Service,PaaS)• 为开发、测试和管理软件应用程序提供按需开发的环境。其核心技术是分布式并行计算。PaaS实际上是指将软件研发的平台作为一种服务。3)软件即服务(Software as a Service,SaaS)• 通过互联网提供按需软件付费应用程序,云计算提供商托管和管理软件应用程序,并允许用户连接到应用程序并通过互联网访问应用程序。客户可以自己定制、配置、组装来得到满足自身需求的软件系统。云关键技术• 虚拟化技术• 分布式数据存储• 并行计算• 运营支撑管理• 大数据的特征一般采用5V来描述:1、多样性(Variety):数据类型繁多。除了以往的以文本为主的结构化数据,非结构化数据越来越多,如音频,视频,图片,地理位置信息等。2、速度(Velocity):处理速度快。一方面是数据的增长速度快,另一方面是要求数据访问、处理、交付的速度快,通常要求具有时效性。是大数据区别于传统数据挖掘的最显著特征。3、大量(Volume):数据体量巨大。聚合在一起供分析的数据规模非常庞大。4、价值(Value):价值密度低。大数据的本质是需要从海量数据中获取具有高价值的数据。5、真实性(Veracity):是指数据是来自于各种、各类信息系统网络以及网络终端的行为或痕迹。大数据处理流程• 从大数据生命周期的角度看,大数据处理的基本流程包括:数据采集、数据分析和数据解释DB(数据库):是 “操作记录系统” ,负责 “干当前活”。DW(数据仓库):是 “历史分析平台” ,负责 “看过去事、谋未来策”。在多维数据模型中,数据被视为数据立方体(Data Cube),由维(Dimensions)和度量(Measures)组成。维是观察数据的角度(如时间、地点、产品),度量是要分析的具体数值(如销售额、数量)。度量有时也被称为事实数据仓库(DataWarehouse, DW),是建立决策支持系统的重要技术手段,是建立决策支持系统的基础。数据仓库的数据具有四个基本特征:面向主题的、集成的、不可更新的、随时间不断变化面向主题的通俗说:数据按“分析什么”来整理,而不是“谁在用”。比如,你想分析“销售情况”,传统业务系统里销售数据可能分散在订单、财务、物流等多个系统里。而数据仓库会把所有跟销售相关的数据(卖了什么、谁买的、什么时候卖的、利润多少……)都抽出来,整理在一起,专门给你分析“销售”这个主题用。集成的通俗说:把各处乱糟糟的数据“翻译”成统一的语言,拼成一张完整的图。公司里不同部门的数据往往“各说各话”:财务系统里商品编码是 A001,销售系统里叫 SP-001;有的用“元”做单位,有的用“万元”。数据仓库会把这些数据全部清洗、统一格式和含义,让它们能互相“对话”,形成一个整体。不可更新的通俗说:存进去就像“拍照片”,只读不改,保证历史真实。数据仓库里的数据一旦存进去,基本就不修改了。它记录的是过去某个时刻的“快照”,比如2023年1月1日的销售额。这样,你分析历史趋势时,数据不会变来变去,保证结果可靠。随时间不断变化的通俗说:数据都带着“时间标签”,能看趋势、比变化。数据仓库里的数据天然包含时间维度,会持续不断地把新的历史数据加进来(比如每天新增前一天的销售数据)。这样你就能分析“过去三年销量如何增长”“今年比去年哪个月更好”这类问题。DM (Data Mining,数据挖掘) 的学科渊源。数据挖掘是从 机器学习 (Machine Learning) 演变发展而来的重要技术领域,它利用机器学习算法从大量数据中发现模式和知识。分类和聚类区别分类是“按已知标签分”,聚类是“按未知相似性聚”。数据挖掘五大核心任务一句话核心区别分类 vs 聚类:分类是 “按已知标签分”(有老师教);聚类是 “按相似性聚”(自己琢磨)。关联规则:找 “如果…那么…” 的搭配规律。异常检测:找 “少数派” 和 “捣蛋鬼”。回归:预测一个 具体的数字(比如价格、销量),而不是类别。
-
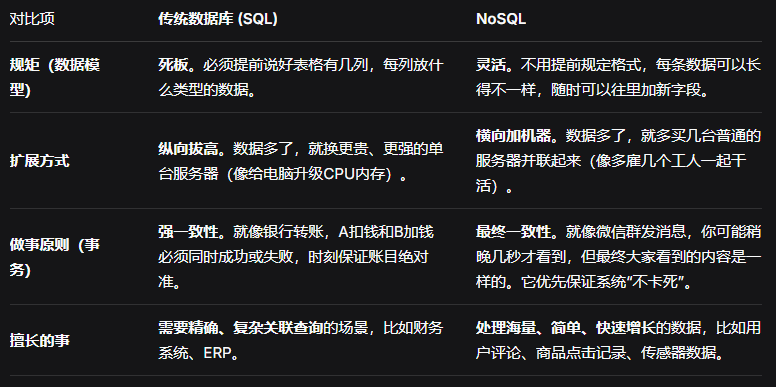
nosql知识点 它到底是个啥?{card-default label="NoSQL 数据库" width=""}NoSQL 你可以理解为 “不全是SQL” 或者 “非关系型数据库”。传统数据库(SQL):像 Excel 表格。数据必须整整齐齐地放进预设好的列里(比如姓名、年龄、性别),规矩很严。NoSQL 数据库:像 收纳盒或者文件夹。你可以随意往里扔各种东西(一段文字、一张照片、一个合同),每个东西贴个标签就行,非常灵活。它的出现,主要是为了搞定现在互联网上海量、杂乱、访问速度要求极高的数据。{/card-default}为什么需要它?(和传统数据库比有什么不一样?)想象一下传统数据库是个严谨的图书馆管理员,而 NoSQL 是应对双十一抢购的超级仓库管理员。NoSQL 的四大门派它们存储数据的方式不同,就像不同的收纳工具。{card-default label="键值数据库 【万能标签盒】" width=""}怎么存:每一个数据都贴一个唯一的标签(Key),然后直接扔进盒子里(Value)。这个“值”可以是任何东西。特点:拿取速度极快(知道标签名,一拿一个准),但只能通过标签找,不知道里面具体是啥。例子:用户会话ID: {用户信息JSON}, 商品ID: 库存数量。代表:Redis(它像一个带分类格的速度超快的标签盒)。一种专门用于缓存数据库查询结果、减少数据库访问次数的高性能分布式内存对象缓存数据库。Memcached 正是此类系统的典型代表,它通过在内存中缓存键值对数据来加速动态Web应用,提高可扩展性。Redis是一个开源的内存数据结构存储,用作数据库、缓存和消息代理。它支持多种数据结构,如字符串、哈希、列表、集合、有序集合等。Redis在内存中运行,但它也提供持久化选项,可以将数据保存到磁盘。有两种主要的持久化方式:RDB(周期性快照)和AOF(追加日志)。Redis支持主从复制,可以实现数据备份和读写分离{/card-default}{card-default label="文档数据库 —— 【文件夹档案柜】" width=""}怎么存:每个数据是一个自成一体的“文档”(比如一个JSON文件)。这个文档里面有各种属性和值,可以嵌套。特点:很灵活。一个人的档案里,可以有基本信息、多个地址、多个爱好列表。想加新信息(比如“驾照号”),直接往新文档里加就行,不影响老文档。例子:一个用户的全部信息(基本信息、订单、地址)都保存在一个JSON文档里。代表:MongoDB(最流行的文档柜)。MongoDB是一个文档数据库,它以BSON(Binary JSON)格式存储数据。BSON是一种二进制编码的JSON-like格式。它用于MongoDB中的数据存储和网络传输。BSON 是具体的二进制编码格式。 MongoDB 在网络传输和存储时使用 BSON,而非纯 JSON(尽管查询和导出可能使用 JSON 表示)。MongoDB的逻辑结构类似于传统关系数据库,但术语不同。MongoDB中,数据层次为:数据库(Database) -> 集合(Collection) -> 文档(Document)。MongoDB中没有“表(table)”的概念,对应的概念是“集合(collection)”。因此,“表table”不属于MongoDB的逻辑结构。MongoDB 的核心特性包括面向文档的数据模型、通过复制集实现的高可靠性以及通过分片实现的可扩展性。虽然从 4.0 版本开始支持多文档 ACID 事务,但事务并非其最标志性的特性,传统描述中更强调高可靠性和分片。{/card-default}{card-default label="列族数据库 —— 【超级大表格(转置版)】" width=""}怎么存:想象一个无限大的表格,但它是按列存储的。每一行有一个行键(主键),但每一行可以有不同的列。它特别适合存海量的、稀疏的数据。特点:查询某几列的数据巨快,也容易压缩,特别适合做大数据分析。例子:存储全网所有网页。行键是网址,每一列可以存:网页内容、抓取时间、关键词1、关键词2……不是每个网页都有所有列。代表:HBase, Cassandra(谷歌“三驾马车”之一的后代)。BigTable的论文公开后,成为了列族数据库这一NoSQL门派的直接设计原型。Apache HBase 就是BigTable的开源实现。Cassandra 的设计也深受其影响。可以说,没有BigTable,就没有现代列族NoSQL数据库。Google的这三项技术(MapReduce、Chubby、BigTable)对现代分布式系统和NoSQL数据库的发展产生了深远影响。BigTable是一个典型的NoSQL数据库(列族存储),MapReduce是并行数据处理模型(后来演化为Hadoop),Chubby是分布式锁服务。而EC2是亚马逊的弹性计算云(基础设施即服务)HBase 本身是数据库,负责存储和实时读写;当需要进行大规模、复杂的数据处理或分析时,它依赖 MapReduce 这种分布式计算框架来提供强大的计算能力。MapReduce 是 Hadoop 生态中的分布式计算引擎,专门负责对海量数据进行并行处理、分析和转换。它们如何协作?数据存在哪:HBase 的数据实际存储在 HDFS(Hadoop 分布式文件系统) 上(A选项)。HDFS 提供的是存储能力。数据怎么算:当你需要对 HBase 中的海量数据进行复杂分析(比如全表扫描、聚合统计、数据挖掘)时,HBase 会作为 MapReduce 作业的输入源。MapReduce 会并行读取 HBase 的数据,分布到多台机器上进行计算,最后汇总结果。这就是 “强大的计算能力”。集群怎么管:HBase 依赖 ZooKeeper(D选项) 来管理集群状态、实现主节点选举和元数据协调。它提供的是协调能力,不是计算能力。Chubby(B选项) 是 Google 内部的分布式锁服务,HBase 不使用它假设你有一个存储在 HBase 中的十亿条用户行为记录。HBase 本职工作:快速查询某个用户的最近10条行为(通过行键)。当需要回答:“过去一个月,所有用户中点击量最高的前10个商品是什么?” 这种涉及全量扫描和排序的问题时,就需要 MapReduce 出动。它会启动一个计算任务,并行扫描所有数据,进行统计排序,最终给出结果。{/card-default}{card-default label="图数据库 —— 【人际关系网】" width=""}怎么存:用 “节点” (实体,比如人、公司)和 “边” (关系,比如朋友、任职)来存储数据。重点就是描述事物之间的联系。特点:查找关系的能力无敌。专门回答“朋友的朋友中,谁和我有共同爱好?”这类问题。例子:社交网络(谁认识谁)、反欺诈系统(识别复杂洗钱路径)、推荐系统(通过喜好关联商品)。代表:Neo4j。Neo4j作为图数据库,其核心数据模型包括节点(Node)、关系(Relationship)和属性(Property)。节点代表实体,关系代表实体之间的连接,属性则是附着在节点和关系上的键值对。{/card-default}{dotted startColor="#ff6c6c" endColor="#1989fa"/}两个必须懂的核心理论{callout color="#f0ad4e"}1.CAP定理 —— “鱼与熊掌不可兼得”在分布式系统(多台机器一起工作)里,有三个好属性:C - 一致性:所有机器上的数据在同一时刻是一样的。A - 可用性:每次请求都能收到响应(不管成功还是失败)。P - 分区容错性:即使机器之间网络断了,系统整体还能工作。CAP定理说:当网络故障(P一定发生)时,你只能在C和A中选一个保。选 CP:保证所有机器数据一致,但可能在同步数据时让用户等一会儿(牺牲一点可用性)。像银行核心系统。选 AP:保证用户随时能访问,但不同机器上的数据可能短暂不一致(牺牲强一致性)。像网站商品库存显示。2.最终一致性 —— “等等就同步了”这是AP系统常采用的策略。意思是,数据更新后,不会立刻同步到所有副本,但保证经过一个很短的时间后,所有副本最终都会变成新数据。就像发朋友圈,不是所有好友都立刻看到,但过一会儿刷,大家就都看到了。{/callout}优点和缺点(大实话)优点:能“长大”:数据多了,加便宜机器就行,扩展简单。速度快:为简单查询而生,没有复杂关联,所以贼快。很随和:数据结构说变就变,适合需求经常改的互联网项目。缺点:不“严谨”:很难做到像银行转账那样精确的复杂事务。查询弱:不适合做多表关联、复杂报表分析。得学新招:每种NoSQL都有自己的操作方式,得重新学习。什么时候该用NoSQL?你的数据量非常大,而且增长飞快。你需要极高的读写速度(比如秒杀、点赞)。你的数据结构经常变化,或者本来就是半结构化/无结构的(比如JSON日志、用户生成内容)。你的应用需要轻松地在多台机器上水平扩展。总结可以把数据库工具想象成交通工具:SQL数据库 像一辆精密的轿车,适合在规则明确的高速公路(稳定业务)上,安全、准确地把你和家人(关联数据)送到目的地。跑长途(复杂分析)很稳。NoSQL数据库 像一队灵活的皮卡或集装箱卡车,适合在工地(快速迭代的业务)上,运送大量、各式各样的货物(海量多样数据)。拉货能力强,但坐起来没那么舒服(事务弱)。没有谁最好,只有谁更合适。 现在很多大公司都是“混搭风”,核心交易用SQL保证正确,海量日志和缓存用NoSQL追求速度。在分布式数据库中,垂直分片是指把一个数据表“竖着”切成多个部分,每个部分包含原表的一部分列。比如一个学生表有学号、姓名、年龄、成绩等列,可以切成两个分片:一个包含学号、姓名,另一个包含学号、年龄、成绩。为了保证把这些分片重新拼凑起来能得到完整的原始表(可靠重构),并且尽量不重复存储数据(最小冗余),分片设计必须满足一个关键条件:每个分片都必须包含原表的主键(比如学号)。为什么?主键是拼接的依据:就像拼图时每个碎片都要有对应的位置标记,主键就是行的唯一标记。每个分片都有主键,才能通过主键把属于同一行的不同列正确连接起来,恢复原表。避免冗余:除了主键,其他列只在其中一个分片中出现,这样就不会重复存储,节省空间。{card-default label="OLAP和OLTP的区别" width=""}想象一家大超市:OLTP(联机事务处理) 就像是 “收银台”。OLAP(联机分析处理) 就像是 “总经理的报表系统”。它们到底在干什么?OLTP — “收银台” (干活的)工作内容:处理一笔笔即时的交易。“扫码这件商品,加入购物车。”“删除刚才误扫的商品。”“插入一条新的会员消费记录。”“更新某个商品的库存数量(卖出一件就减一)。”特点:面向操作人员:收银员、客服、仓库管理员。处理当前数据:关心的是“现在”发生了什么交易。操作频繁且简单:每秒钟要处理无数个“插入、删除、更新”的小操作。目标:保证每一笔当前交易都准确、快速地完成。OLAP — “总经理的报表系统” (分析的)工作内容:基于历史数据,分析趋势,辅助决策。“上个季度,哪个品牌的洗发水在华东地区卖得最好?”“对比过去三年,夏天的饮料销量增长趋势如何?”“如果我们对会员打折,能多带来多少利润?”特点:面向决策人员:总经理、市场总监、分析员。使用历史数据:把过去几个月、几年的销售数据都拿来分析。操作复杂但次数少:一次分析查询可能要扫描几百万条记录,进行复杂的“汇总、分组、对比”,但一天可能只跑几次这样的分析。目标:从海量历史数据中发掘新的信息和规律,帮助做决策。{/card-default}BASE 是三个短语的首字母缩写,描述了分布式系统的三个特性:B - Basically Available(基本可用)大白话:系统始终能响应用户请求,不会彻底挂掉。怎么做到:在出现故障(比如一台机器宕机、网络分区)时,系统可能会牺牲一部分功能或降低一点服务质量(比如返回一个不那么精确的旧数据,或者让查询慢一点),但核心服务仍然可用。例子:双十一期间,淘宝商品详情页的“累计评论数”可能不是实时精确数字(有几分钟延迟),但“加入购物车”和“下单”这个核心功能必须能用。这就是“基本可用”——用部分非核心数据的不精确,换取核心交易流程的不中断。S - Soft State(软状态)大白话:系统中的数据,在某一时刻,不需要所有副本都保持完全一致。怎么理解:与“硬状态”(任何时刻数据都一致且确定)相对。“软状态”允许数据在不同副本之间存在一个中间状态,这个状态可能因同步延迟而暂时不同,并且可能在没有外部输入的情况下,随着时间自我演变(最终达到一致)。例子:你微博点赞后,你的手机立刻显示“已赞”(你的本地副本状态),但这个“赞”的数量可能还没同步到所有服务器,所以你朋友那边看到的点赞数可能还没更新。这个“你已赞但总数未变”的中间过程,就是软状态。E - Eventual Consistency(最终一致性)大白话:只要系统不再接收新的更新,经过一段“同步时间”后,所有副本的数据最终会变成完全一致的状态。这是BASE的最终目标。它不强求“瞬间一致”,但保证“最终一致”。例子:还是微信群消息。只要没人再发新消息,经过几秒或几分钟的同步,所有在线成员的手机都会显示完全相同的聊天记录。NewSQL 的核心特性(三大承诺){callout color="#f0ad4e"}保持 SQL 与关系模型(开发者友好)是什么:完全支持标准 SQL 语言和 ACID 事务。开发者可以用熟悉的JOIN、复杂查询和事务逻辑,几乎无学习成本。为什么重要:这是对传统数据库生态和开发习惯的继承,避免了 NoSQL 需要重写业务逻辑和复杂应用层补偿的问题。完整的分布式 ACID 事务(数据强一致)是什么:在分布式环境(多台机器)下,依然提供跨节点的强一致性事务保证。这是它与大多数 AP 型 NoSQL(最终一致性)的根本区别。技术关键:通过新型分布式共识算法(如 Raft、Paxos)、多版本并发控制(MVCC)、优化的两阶段提交(2PC)等技术实现,在保证一致性的同时尽可能提升性能。透明的弹性水平扩展(运维友好)是什么:像 NoSQL 一样,可以通过简单地增加机器节点来线性提升系统的整体处理能力(写性能和存储容量)。并且这个过程对应用程序是透明的,应用无需感知数据具体分布在哪个节点。技术关键:采用 shared-nothing 架构,并通过自动化分片技术将数据表和索引智能拆分到不同节点。{/callout}弹性云计算 EC2是什么:亚马逊 AWS 提供的弹性计算服务(虚拟机实例)。它是基础设施即服务(IaaS) 的典范。与NoSQL关系:它不属于Google,属于亚马逊。虽然很多NoSQL数据库可以部署在EC2上,但它本身不是数据库技术,而是云计算基础设施。因此,它不属于Google云计算平台技术架构。
-
SQL中通配符%和*的区别 标准SQL中的通配符:%是标准SQL中LIKE操作符使用的通配符,表示匹配任意数量的字符(包括零个字符)例如:LIKE 'abc%'匹配以"abc"开头的所有字符串特定系统中的通配符:*是某些特定系统(如Windows命令行、Unix shell)中使用的通配符在一些数据库工具(如MySQL命令行客户端)的简单模式匹配中也支持*主要区别:在标准SQL查询中必须使用%*通常只在特定工具或非标准扩展中使用例如在MySQL中,*可用于命令行简单查询,但在SQL语句中仍需用%何时用哪个:编写SQL语句时:总是用%使用数据库工具的非SQL模式匹配时:可能用*(取决于工具)在正则表达式中:两者都不是通配符,有完全不同的含义当编写标准SQL时,LIKE操作符总是使用%作为通配符。



0:00