

搜索到
178
篇与
的结果
-

-
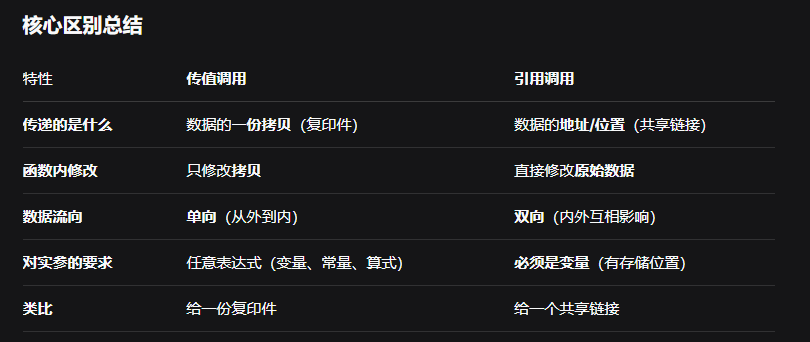
软工知识点 函数调用时实参向形式参数传递相应类型的值,则称为是传值调用。这种方式下形式参数不能向实参传递信息。实参可以是变量,也可以是常量和表达式。引用调用的实质是将实参变量的地址传递给形参,因此,形参是指针类型,而实参必须具有左值。变量具有左值,常量没有左值。被调用函数对形参的访问和修改实际上就是针对相应实际参数所作的访问和改变,从而实现形参和实参间双向传递数据的效果。{callout color="#f0ad4e"}传值调用(就像“复印一份”)做法:你把文件的完整复印一份,把这份复印件交给朋友。朋友的操作:他可以在复印件上任意涂改、做笔记。对你原件的影响:没有任何影响。你手里的原件还是原来那份,干干净净。在编程中的体现:函数内部修改的是“复印件”(形参),而外部的原始数据(实参)完全不变。实参可以是任何数据(变量、数字5、一个算式的结果)。引用调用(就像“共享电子文档链接”)做法:你把文件存储在云盘(如Google Docs),然后只把文件的访问链接(地址) 发给朋友。朋友的操作:他点击这个链接,打开的就是你电脑里的那个唯一原件。他做的任何修改都会直接保存到这份原件上。对你原件的影响:直接影响。你再打开文件,看到的就是他修改后的版本。在编程中的体现:函数内部通过“链接”(地址)直接操作外部的原始数据(实参)。为了实现这一点:实参必须是一个“有位置的变量”(就像一个实际存在的云盘文件)。你不能把一个纯数字(比如5)或者一句话的链接发给别人,因为这些东西没有“存储位置”可供修改。这也就是解析里说的,实参必须有 “左值” (可以简单理解为 “是一个可以存放东西的容器/位置”)。{/callout}为什么只有变量才有存储位置问题简单来说就是内存寻址的概念。计算机中,程序运行时,数据需要存储在内存中特定的位置(地址)。变量在程序中定义时,编译器或解释器会为它分配一块内存空间,因此变量有存储位置(地址)。而常量和表达式的结果(除非被赋给变量)通常是临时性的,它们可能存放在寄存器或临时栈空间,但程序通常不提供直接访问其地址的机制(尤其是常量,往往在编译时就确定了值,可能直接嵌入指令中,没有运行时内存地址)。对于引用调用(传递地址),需要实参有一个固定的、可寻址的内存位置,以便形参(指针)能够指向它,从而通过指针修改其内容。常量没有可修改的内存位置(常量通常存储在只读内存区或直接编码在指令中),表达式的结果是临时值,也没有持久的内存地址(除非先赋给变量)。因此,只有变量(或更广义的左值)才能进行引用传递。左值(lvalue)是一个历史术语,意指可以出现在赋值语句左边的表达式,即它标识了一个可存储对象的位置。变量是典型的左值。常量和算术表达式的结果是右值(rvalue),它们没有可标识的存储位置(或者说是临时值)。引用调用需要左值,因为需要取地址。举例:假设有函数 void f(int &x) { x = 10; }调用时:int a = 5; f(a); // 正确,a是变量,有地址f(5); // 错误,5是常量,没有可修改的地址f(a+1); // 错误,a+1是表达式结果,临时值,没有持久地址因此,引用调用要求实参必须是左值(变量)。
-
-
-
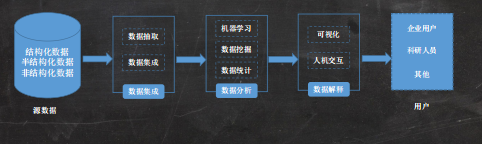
云计算与大数据 权威定义:云计算是一种将可伸缩、弹性、共享的物理和虚拟资源池以按需自服务的方式供应和管理,并提供网络访问的模式。• 狭义:云计算是一种提供资源的网络,使用者可以随时获取“云”上的资源,按需求量使用,并且可以看成是无限扩展的,只要按使用量付费就可以。• 是以一种方便的使用方式和服务模式,通过互联网按需访问资源池模型(例如网络、服务器、存储、应用程序和服务),以快速和最少的管理工作为用户提供服务1、关键特征:• 广泛的网络接入• 可测量的服务• 多租户• 按需自服务• 快速的弹性和可扩展性• 资源池化2、其它关键特征:• 虚拟化技术• 可靠性高• 性价比高1、按云部署模式和云应用范围分类:1)公有云• 一般是被一个云计算服务提供商所拥有,该组织将云计算服务销售给公众,公有云通常在远离客户建筑物的地方托管(一般为云计算服务提供商建立的数据中心)2)社区云• 云的基础设施被一些组织所共享,并为一个有共同关注点的社区服务。可以是该组织或某个第三方负责管理。3)私有云• 云的基础设施是为一个客户单独使用而构建的,因而提供对数据、安全性和服务质量的最有效控制。私有云可部署在企业数据中心中,也可部署在一个主机托管场所,被一个单一的组织拥有或租用。4)混合云• 云的基础设施由以上两种或两种以上的云(私有、社区或公有)组成。2、按云计算的服务层次和服务类型分类:1)基础设施即服务(Infrastructure as a Service,IaaS)• 提供虚拟化的计算资源,如虚拟机、存储、网络和操作系统。其核心技术是虚拟化。2)平台即服务(Platform as a Service,PaaS)• 为开发、测试和管理软件应用程序提供按需开发的环境。其核心技术是分布式并行计算。PaaS实际上是指将软件研发的平台作为一种服务。3)软件即服务(Software as a Service,SaaS)• 通过互联网提供按需软件付费应用程序,云计算提供商托管和管理软件应用程序,并允许用户连接到应用程序并通过互联网访问应用程序。客户可以自己定制、配置、组装来得到满足自身需求的软件系统。云关键技术• 虚拟化技术• 分布式数据存储• 并行计算• 运营支撑管理• 大数据的特征一般采用5V来描述:1、多样性(Variety):数据类型繁多。除了以往的以文本为主的结构化数据,非结构化数据越来越多,如音频,视频,图片,地理位置信息等。2、速度(Velocity):处理速度快。一方面是数据的增长速度快,另一方面是要求数据访问、处理、交付的速度快,通常要求具有时效性。是大数据区别于传统数据挖掘的最显著特征。3、大量(Volume):数据体量巨大。聚合在一起供分析的数据规模非常庞大。4、价值(Value):价值密度低。大数据的本质是需要从海量数据中获取具有高价值的数据。5、真实性(Veracity):是指数据是来自于各种、各类信息系统网络以及网络终端的行为或痕迹。大数据处理流程• 从大数据生命周期的角度看,大数据处理的基本流程包括:数据采集、数据分析和数据解释DB(数据库):是 “操作记录系统” ,负责 “干当前活”。DW(数据仓库):是 “历史分析平台” ,负责 “看过去事、谋未来策”。在多维数据模型中,数据被视为数据立方体(Data Cube),由维(Dimensions)和度量(Measures)组成。维是观察数据的角度(如时间、地点、产品),度量是要分析的具体数值(如销售额、数量)。度量有时也被称为事实数据仓库(DataWarehouse, DW),是建立决策支持系统的重要技术手段,是建立决策支持系统的基础。数据仓库的数据具有四个基本特征:面向主题的、集成的、不可更新的、随时间不断变化面向主题的通俗说:数据按“分析什么”来整理,而不是“谁在用”。比如,你想分析“销售情况”,传统业务系统里销售数据可能分散在订单、财务、物流等多个系统里。而数据仓库会把所有跟销售相关的数据(卖了什么、谁买的、什么时候卖的、利润多少……)都抽出来,整理在一起,专门给你分析“销售”这个主题用。集成的通俗说:把各处乱糟糟的数据“翻译”成统一的语言,拼成一张完整的图。公司里不同部门的数据往往“各说各话”:财务系统里商品编码是 A001,销售系统里叫 SP-001;有的用“元”做单位,有的用“万元”。数据仓库会把这些数据全部清洗、统一格式和含义,让它们能互相“对话”,形成一个整体。不可更新的通俗说:存进去就像“拍照片”,只读不改,保证历史真实。数据仓库里的数据一旦存进去,基本就不修改了。它记录的是过去某个时刻的“快照”,比如2023年1月1日的销售额。这样,你分析历史趋势时,数据不会变来变去,保证结果可靠。随时间不断变化的通俗说:数据都带着“时间标签”,能看趋势、比变化。数据仓库里的数据天然包含时间维度,会持续不断地把新的历史数据加进来(比如每天新增前一天的销售数据)。这样你就能分析“过去三年销量如何增长”“今年比去年哪个月更好”这类问题。DM (Data Mining,数据挖掘) 的学科渊源。数据挖掘是从 机器学习 (Machine Learning) 演变发展而来的重要技术领域,它利用机器学习算法从大量数据中发现模式和知识。分类和聚类区别分类是“按已知标签分”,聚类是“按未知相似性聚”。数据挖掘五大核心任务一句话核心区别分类 vs 聚类:分类是 “按已知标签分”(有老师教);聚类是 “按相似性聚”(自己琢磨)。关联规则:找 “如果…那么…” 的搭配规律。异常检测:找 “少数派” 和 “捣蛋鬼”。回归:预测一个 具体的数字(比如价格、销量),而不是类别。



0:00